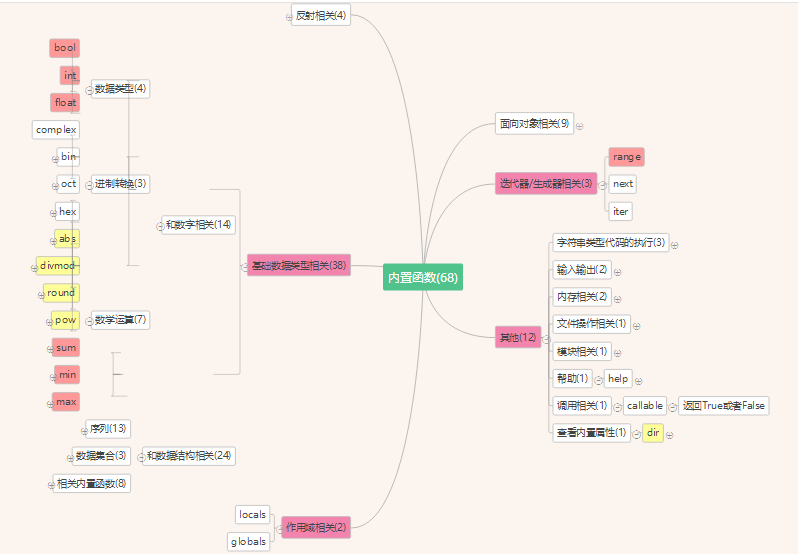

一层内置函数 >>>>二层基础数据类型>>>>三层和数字相关14个 四层数据类型4个 1 布尔值 ***bool 只有True 和False,并且首字母必须是大写。 True: 1 int(非0), 2 str(非'') 非空: True False: 1 int(0), 2 str('') 空: 0,“”,{},[],(),set() 2 数字 ***int int 应用于 :+ ,- ,* ,/ ,** ,% , 例:int1 = 2 int2 = 12 int3 = int1 + int2 int3 = int1 - int2 int3 = int1 * int2 int3 = int1 / int2 3 浮点数(小数)***float 特点: 在取值中 会取值一定的位数 print(float (1.343)) a= 3.141592653123456789 print(a) 3.141592653123457 保留15,16位小数 且最后一位是四舍五入 不太理解 4 复数 complex 复数由 a + bj : 实部和虚部组成 实数 :1 虚部:j -1的平方 3+ 4j < 5 +2j 错误 复数不能比较 四层 进制转换3个 print(bin(20)) print(oct(20)) print(hex(20)) 0b10100 0o24 0x14 1 二进制 bin() 0b10100 2 八进制 oct() 0o24 3 十六进制 hex() 0x14 四层 数学运算 7个 1 计算绝对值 **abs() l1 = [1,3,5,-2,-4,-6] l2 = sorted(l1,key=abs) print(l1) print(l2) 2 返回取(商,余) **divmod() ret = divmod(8,3) ret1 =divmod (8,2) print(ret) print(ret1) (2,2) (4,0) 3 小数精确 **round(x,n)n为保留小数 具有四舍五入的应用 print(round(2.12133112,2)) 2.12 print(round(2.12733112,2)) 2.13 4 幂运算 **pow() (x,n) x**n (x,n,y) x**n\y 取商余数 和divmod 比较直接输出余数 >>> 分2种情况 print(pow(2,3)) print(pow(2,3,4)) print(pow(2,3,3)) 8 0 2 1 pow(x,y) x**y 2pow(x,y,z) x**y%z 5 求和 sum(iterable,start) *** iterable参数必须是一个可迭代数字集 start指出求和的初始值。start+iterable中的值为最终的和 print(sum([1,2,3])) print(sum([1,2,3],2)) 2 为初始值 print(sum([1,2,3],[3,4])) 打印报错 因为([1,2,3],[3,4])不是可迭代对象 print(sum(range(100))) 6 8 4950 6 计算最小值min() >>>>分2种情况 字母比较也是一样的 a print({},1) {} c min({1,2,3,4,5},key=lambda n:abs(n)) print( min({1,2,3,4,5},key=lambda n:abs(n))) 1 print(min({1, 2, 3, 4, -5}, key=abs)) 1 插入小知识 lambda 是匿名函数的关键字相当于def 固定格式 函数名 = lambda 参数(n):返回值n**n(n的条件) print(函数名(参数的值n)) a和b 是一样的 a def add(x,y): return x +y print(add(1,2)) b add=lambda x,y: x+y print(add(1,2)) 2 min(*args,key,defult) 6 计算最大值max() 字母比较也是一样的 a >>>分2种情况 1 max(iterable,key,defult) dic = {'k1':10,'k2':100,'k3':30} print(max(dic)) k3 因为此时比较的是ascii 码的大小 lis = [1,3,6,-22] print(max(lis ,key=lambda k :k)) print(max(lis ,key=abs)) 6 -22 2 max(*args,key,defult) dic = {'k1': 10, 'k2': 100, 'k3': 30} print(max(dic, key=lambda k: dic[k])) k2 条件是dic[k] 值最大的键 一层内置函数 >>>>二层基础数据类型>>>>三层和数据结构相关24个 四层序列13个>>>列表和元祖2个 1 列表 ***list 增加 1append 增加到最后一个列表 li = [1, 3, 4, 'wang', ] li.append('wangyan') print(li) [1, 3, 4, 'wang', 'wangyan'] 2insert 插入, xx.insert(3)表示列表里第2位插入,此处是内容) li = [1, 3, 4, 'wang', ] li.insert(3, 'wangyan') print(li) [1, 3, 4, 'wang',‘wangyan’] li = [1, 3, 4, 'wang', ] 3 # extend 迭代的添加 添加的元素分开了叠加,也就是extend后如果是字符串(‘ABC’)后边则是'A', 'B', 'C',如果后边是[] li = [1, 3, 4, 'wang', ] li.extend([1, 2, 3, 'www']) print(li) [1, 3, 4, 'wang', 1, 2, 3, 'www'] li.extend([1, 2, 3, 'www']) 则变成[1, 2, 3, 'www'] li = [1, 3, 4, 'wang', ] li.extend('luodan') print(li) [1, 3, 4, 'wang', 'l', 'u', 'o', 'd', 'a', 'n'] 二删除 # 1pop 按照索引去删除,有返回值, 此时注意压栈思想 和insert用法类似 。pop(索引对应的值,数字是多少就是列表的数字的N - 1)删除那个 li = [1, 3, 4, 'wang', ] li.pop(3) print(li)[1, 3, 4] li = [1, 3, 4, 'wang',] li.pop() print(li)
[1, 3, 4 ] 2remove 按照元素去删除说白了就是删除名字就行
例如1'wang' li = [1, 3, 4, 'wang', ] li.remove('wang') print(li)[1, 3, 4] 3clear 列空列表结果[] li = [1, 3, 4, 'wang', ] li.clear() print(li) 4del 用法和正常的键盘删除基本几样 区别.pop.remove.clear 直接del[] 删除列里面切片 取值在删除 li = [1, 3, 4, 'wang', 'True', 33, 'yy'] del li[3:6:2] print(li) [1, 3, 4, 'True', 'yy'] 三改 先切片 在删除 在改正 1 字符串的 li = [1, 3, 4, 'wang', 'True', 33, 'yy'] li[1:4] = '宝宝' print(li) [1, '宝', '宝', 'True', 33, 'yy'] 切片后先删除 4 ‘wang’ 变为2位 ‘宝’宝 ‘宝’ 并且迭加 2,后边的是列表[] 取片删除后进行在删除的位置合并 li = [1, 3, 4, 'wang', 'True', 33, 'yy'] li[1:3] = ['ad', 'efe', 'eded', 'wian'] print(li) [1, 'ad', 'efe', 'eded', 'wian', 'wang', 'True', 33, 'yy'] 四查 切片 查看 li = [1, 3, 4, 'wang', 'True', 33, 'yy'] print(li[3:6]) ['wang', 'True', 33] li = [1, 3, 4, 'wang', 'True', 33, 'yy'] del li print(li) 结果为空的 打印长度 li = [1, 'dfs', 23, 87] print(len(li)) 2 元祖*** tuple 元组被称为只读列表,即数据可以被查询,但不能被修改,所以,字符串的切片操作同样适用于元组。 例:(1,2,3)("a","b","c") 一层内置函数 >>>>二层基础数据类型>>>>三层和数据结构相关24个 四层序列13个>>>相关内置函数2个 1 反转 **reversed() 迭代器的 recersed() 迭代器 1 新生成一个列表不改变原列表 2 有返回值还是一个迭代器 2还有个是就是强转的list(ret) reserse() 反转 1 不会生成一个列表改变原来的列表 2 返回值是Npne l = [1, 3, 5, 4, 2, 7] ret = reversed(l) print(ret) print(list(ret)) 迭代器 [7, 2, 4, 5, 3, 1] l = [1, 3, 5, 4, 2, 7] l.reverse() print(l) [7, 2, 4, 5, 3, 1] 拓展 sort() 是从小到大排序 sort() reversed() li = [1,3,5,6,4,2] li.sort() print(li) li.reverse() print(li) [2, 4, 6, 5, 3, 1] 列表反转 li = [2, 4, 6, 5, 3, 1] li .sort(reverse = True) print(li) [6, 5, 4, 3, 2, 1] 列表倒序 2 slice 切片 转成元祖 l = (1,2,23,213,5612,342,43) sli = slice(1,5,2) print(l[sli]) (2, 213) 一层内置函数 >>>>二层基础数据类型>>>>三层和数据结构相关24个 四层序列13个>>>字符串9个 1 字符串***str a 带引号的都是字符串 三引号 可以跨行 name = '郭鹏达'name2 = "王岩" 例: msg = ''' 字符串 '' b 字符串拼接。 字符串加法和乘法。 S1 = ‘abc’ s2 = ‘123’ print(s1 + s2) ‘abc123’ 2 .format() 大括号内是改变输出前的内容 大括号内空 和。format() 一一对应 li = ['alex','eric','rain'] # # 利用下划线将列表的每一个元素拼接成字符串"alex_eric_rain" info = "{}_{}_{}".format(li[0],li[1],li[2]) print(info) #第一种: 大括号内是改变输出前的内容 大括号内空 和。format() 一一对应 ret18 = 'name :{},sex:{},hig:{}'.format("王岩","男",174) print(ret18) name :王岩,sex:男,hig:174 3 字节 *** bytes 1 acsic码 基本不用 不同编码之间互用会产生乱码, 2 unicode A 字母 4个字节 00000000 00000000 00100100 01000000 中 文 4个字节 00000000 00000000 00100100 00000000 3utf-8 中文 A 字母 1个字节 00000001 欧 洲 2个字节 00000000 00000000 00100100 00000000 亚洲 中文 3个字节 00000000 00000000 00000000 00100100 0000000 4 gbk A 字母 2个字节 00000000 00001000 中文 亚洲 2个字节 00100100 00000000 bytes :表现形式: s = ‘Q’ b1 = s.encode ('utf-8') print (b1) b1 = b'Q' 内部存储是(utf-8 ,gbk ,gb232等) s1 = '晓梅' b11 = s1.encode('utf-8') 表现形式: s = b'\xe6\x99\x93\xe6\xa2\x85' (utf-8,gbk,gb2312.....)010101 0000 1000 0000 0000 0000 0001 0000 1001 0000 0000 0000 0001 注意:在utf-8 的情况下b 后边有6个 (e6 99 等) 说名 晓梅 是中文 utf-8 是两个字6个字节 4 bytearray 5 memoryview 6 ord 字符按照unicode转数字 7 chr 数字按照unicode转字符 8 ascii 只要是ascii码中的内容,就打印出来,不是就转换成\u 9 **rep 用于%r格式化输出 区别就是 输出什么就是什么 注意引号 print('name,%r'%'金老板') name,'金老板' print('name,%s'%'金老板') name ,金老板 一层内置函数 >>>>二层基础数据类型>>>>三层和数据结构相关24个 四层序列13个>>>数据集合3个 1 **字典 字典相关的代码 1、字典的特性:a 字典的无序性; b 数据关联性强 C 键键值对 唯一一个映射数据类型 字典的键必修二是可哈希的(不可变的数据类型:,字符串,数字的,布尔值,元祖) 并且是唯一的 不可哈希的(可变的数据:列表,字典,set 集合) 例子 , dic = {'name':'aima','age':43} 2 增加 a、 增加 dic ['k'] = v 直接可覆盖 dic['name'] = 'wangyan' b 、dic.sedefault ('k') 有键值对不做任何改变,没有键值对才添加 dic = {'name':'aima','age':43,'sex':'men'} dic['name'] = 'wangyan' print(dic) dic.setdefault('goodmen','wangyan') print(dic) 有键值 不做任何反应还是原来的字典 ,没有的就添加新的 3 、删除 a .pop() 删除一个键 就删除一个组 dic.pop('name') print(dic) 压栈思想 .pop() 默认返回最后一个值 li=[] l = [1,2,3,4,5] l1 = l.pop() print(l1) 5 b 、del 直接删除k 键 del dic['age'] print(dic) dic = {'name':'aima','age':43,'sex':'men'} 4 改 a 和第一种增加一样 覆盖 dic['name'] = 'luodan' print(dic) b .update() dic1 = {'boy':'wangmutian'} dic .update(dic1) print(dic) {'name': 'aima', 'age': 43, 'sex': 'men', 'boy': 'wangmutian'} 5 查 直接打印k 就能得到V的值 但是如果没有k键 就会报错 提示None a 直接打印k for key in dic: print(key) name age sex b for i in dic.keys(): for i in dic.keys(): print(i) for i in iterms 打印出来的是键值对 6重要的格式 一定要记住!!!!!!!!! 低级尽量不用 dic = {'name':'aima','age':43,'sex':'men'} for key,value in dic.items(): print(key,value) name aima age 43 sex men for key in dic: print(key,dic[key]) dic = {'name':'aima','age':43,'sex':'men'} 7列表变成字典 如果后边有1 ,就是值 否则[]里面都是k 值 分别给键对值 dic = dict.fromkeys(['22',(1,2),'wangyan','zhang'],'kk') print(dic {'22': 'kk', (1, 2): 'kk', 'wangyan': 'kk', 'zhang': 'kk'} 固定格式 一定的是 dic = dict.fromkeys() 针对于多个键 对应一个值的方法 ) --------------- 2 **集合 集合是无序的 元素是可哈希的(不可变的数据类型:int str tuple bool ) 但是集合本身是不可哈希的(可变的数据类型) 所以做不了字典的键 主要是用于去重 a 每次打印都是无序的 都不一样的 set = {1,'wag',4 ,'Tru',3} print(set) set = {1,'wag',4 ,'Tru',3,3} print(set) 直接打印去重 b 集合的增删改查 增加 。add() .update 删 。pop 改 查 for i in set1 c 集合的交集 并集 反交集 交集&(and) 取公共部分 差集(-) 取set1 交集以外的set1 并集 取所有的 但是重复部分取一次 用|表示 set(lis)&set1(lis2) set(lis)-et1(lis2) set1 ={1,2,3,4} set2 ={2,3,4,5,6,7,8} 交集 print(set1&set2) {2, 3, 4} 去重 并集 | 表示 print(set1|set2) {1, 2, 3, 4, 5, 6, 7, 8} 差集 print(set1-set2) {1} 3 **冷冻集合 暂无资料 set1^set 非集合 一层内置函数 >>>>二层基础数据类型>>>>三层和数据结构相关24个 四层序列13个>>>相关内置函数8个 1 **len() 长度 字符串 列表 包含空 lis = [1,4,3,2] print(len(lis)) s = 'wangyanluodanwangmutian ' s1 = 'wangyanluodanwangmutian' print(len(s)) print(len(s1)) 4 25 23 2 **枚举,对于一个可迭代的(iterable)/可遍历的对象(如列表、字符串), enumerate将其组成一个索引序列,利用它可以同时获得索引和值。 就是打印列表的索引和值 li = ['alex','银角','女神','egon','太白'] for i in enumerate(li): print(i) (0, 'alex') (1, '银角') (2, '女神') (3, 'egon') (4, '太白') for index,name in enumerate(li,1): print(index,name) 1 alex 2 银角 3 女神 4 egon 5 太白 3 all 判断是否有bool值为False 的值 4 any 判断是否有bool值为True 的值 5 **zip 返回一个迭代器必须有个list 转化 拉链 以最短的为基准 将两个列表整合成两个列表 分别取值 print( list(zip([1,2,3,4,5],[2,3,4]))) [(1, 2), (2, 3), (3, 4)] 6 filter 过滤 通过函数的定义过滤 # 题目 用filter过滤方法 处理里面的偶数 # 三元运算 注意了没有 标点 True if n %2 ==0 else False # li =[1,2,3,4,5,6,7,8] # def func(n): # if n %2==0: # return n # print(list(filter(func,li))) # ret = filter(lambda n:True if n %2 ==0 else False,li) # print(list(ret)) # for i in ret : # print(i)
def small(x): if x < 10: return True ret = filter(small,[1,4,3,22,55,33]) print(list(ret)) [1,4,3] def small(x): return x % 2 == 1 ret = filter(small,[1,4,3,22,55,33]) print(list(ret)) 7 map 返回一个新的列表
map函数应用于每一个可迭代的项,返回的是一个结果list。如果有其他的可迭代参数传进来, map函数则会把每一个参数都以相应的处理函数进行迭代处理。 map()函数接收两个参数,一个是函数,一个是序列, map将传入的函数依次作用到序列的每个元素,并把结果作为新的list返回。
1 题目 名字前面加hr_.
第一种 li = ['wangyan','luodan','wangyanmutian'] def nam(n): return 'hr_'+n print(list(map(nam,li))) ['hr_wangyan', 'hr_luodan', 'hr_wangyanmutian']
for i in ret: # print(i)
hr_wangyan
hr_luodan hr_wangyanmutian第二种
print(list(map(lambda n: 'hr_'+n,li))) 要是不要列表直接for 循环
map (函数,列表) L = [1,2,3,4,] def pow2(x): return x*x print(list(map(pow2,L))) 8sorted l1 = [1,3,5,-2,-4,-6] l2 = sorted(l1,key=abs) print(l2) 一层内置函数 >>>>二层作用域相关 1 global 改变全局的 n = 1 def func(): global n n = n +1 print(n) print(n) func() print(n) 1 ,2,2 2 local 的内容会根据执行位置来决定作用域中的内容 如果在全局执行 和globals() 一样 3 nonlocl 修改最近拥有该变量的外层函数 不影响全局 n = 1 def func1(): n = 2 def func2(): nonlocal n n+=1 print(n) func2() func1() print(n) 答案 是 3 引用上级的, 1 全局的 一层内置函数>>>>二层迭代器/生成器相关(3) 判断是不是可迭代对象 print('__iter__'in dir(对象)) print(isinsstance(对象),iterable ) 迭代器的含义 含有 .__iter__() 的 且比可迭代对象多一个next 方法 方 法 next iter 两个个用法 生成器的含义本质 生成器的本质就是迭代器 方法 1 iter 可迭代对象的一个方法 2 next 迭代器的比可迭代对象多个方法 3 ***range yield py关键字 genertaor 生成器 含有yield的话就变成了生成器 条件有二 1是有yield 2函数的调用 3 print(g) 是 F 或者T 是不是生成器??? 4 打印t(g._next_()) 打出来就是yield 后面 例子 打印出100件衣服 标上序号 def cloth(): for i in range (100): yield ('衣服%s'%i) g = cloth() 1 一件一件的打印 print(g.__next__()) 2打印前50件 for i in range(50): print(g.__next__()) 3全打出了来 for i in g: print(i) 一层内置函数>>>>二层迭代器/生成器相关(3)>>>>其他>>>>字符串类型代码的实行3个 注意这个三个尽量不要用 或者请示领导再用 1 **eval 执行 有返回值的 可以拿到结果的 针对字符串的 可以直接运算出结果来 记住针对字符串的 2 **exec 用于流程性代码的执行 print(exec('1+3-3-1')) print(eval('1+3-3-1')) None 0 3 compile 编译 一层内置函数>>>>二层迭代器/生成器相关(3)>>>>其他>>>>输入输出2个 1 ***input 用户交互 name = input ('请输入内容') 必须是str 2 ***print 打印出内容 默认是sep = ',' print(1,2,3,4,5 ,sep = '*') 1*2*3*4*5 一层内置函数>>>>二层迭代器/生成器相关(3)>>>>其他>>>>内存相关2个 id hashi函数是一个算法 结果是一个数字 每次数字不一样的 存储和查找 只要不可变就是 1 ***hash 可哈希(不可变) 不可哈希(可变) 2 id 内存地址 print(id('wangyan')) print(hash('wangyan')) 每次打印的数字都是u不一样的 一层内置函数>>>>二层迭代器/生成器相关(3)>>>>其他>>>>文件操作相关(1) 1 **open f = open('文件名',encoding = 'utf-8') 打开模式 有 默认 r 读模式 w 写模式 清空 a 不可读 追写文件的最后 没有则创建 b 以字节的形式打开 一层内置函数>>>>二层迭代器/生成器相关(3)>>>>其他>>>>模块相关(1) 1 ***import import os os.remove() os.rename('old','new') import time start = time.time() end = time.time() 一层内置函数>>>>二层迭代器/生成器相关(3)>>>>其他>>>>查看(1) 在pyxm 左键单击 help 包含所有的用法 in dir 只包含方法名字 1 help a 直接help 退出 q b help(数据类型) 制定查看某对象的帮助信息 一层内置函数>>>>二层迭代器/生成器相关(3)>>>>其他>>>>调用相关(1) 1 callable 是否可以调用 返回布尔值 a = [1,3,4,6] print(callable(a)) print(callable(print())) print(callable('abc')) 全是False 2 **dir 1 查看内置属性 dir(__builthin__) 2 查看某对象的属性及方法 dir()